
My homelab
Introduction
I use my homelab as a mix of learning new stuff and also because its my hobby to tinker with servers, software and to program stuff.
I use mostly exclusively SuperMicro motherboards and a mix of SuperMicro cases and other brands of cases.
My homelab started many years ago in 2001 with a Sun Fire V100 1U server.
It ran under my desk making an awful noise and served my website at that time, plus an archive of a mailing list that I was reading. And also served as a development server where I tested the java programs I built at that time. Since then I have had no servers at all and when I started having a “server” again, it was a normal desktop board running with an Intel Core I5-2500S. Since then it escalated at first slowly with a QNAP NAS and then quickly to its current form. Before the current iteration of the homelab I also had a Dell PowerEdge VTRX blade system running for a short while, but I never took it into production since it simply made too much noise and consumed too much power for my appetite.
If I had a room that I could dedicate to my servers - a room that Í could sound proof - I would probably relax my criteria for what kind of hardware I would like to have running.
This is my current homelab.
Servers
My homelab consists of:
- Main VM Host
- Secondary VM Host
- Backup VM Host
- NFS Server for VMs (Virtualized inside Main VM Host)
- Storage Backup Server
- Firewall
- 1Gbps Fibre connection to the internet
- Netgear XS708T 10Gbps
- Netgear S3300-28X
- APC SmartUPS 2200i
- A couple of 8 port unmanaged switches
Most of my gear is crazy overpowered for my needs, but the need for speed is hard to resist.
I will go through my servers in the order of their “size” and “performance”.
This server is the tiniest of the bunch and is only running my failover DNS and DHCP servers, so when I am doing maintenance on my main VM host, then I still have DNS+DHCP for my network, which means I can both do VM maintenance on my primary DNS & DHCP or shut down the Main VM host entirely and my network will still work.
Where the Secondary VM host was underpowered - my firewall is way overpowered because not very much traffic needs to be protected, but the reason why I use this board for my firewall and not the AsRock motherboard (which was my firewall at some point) - is that I do not like that I have to put a monitor and keyboard to a server in case something goes wrong. The SuperMicro board have a ASPEED AST2400 BMC which enables me to connect to the server even while the OS cannot boot and control it like I was sitting in front of it. So its for peace of mind that I use this and to make it easier when shit hits the fan, which unfortunately it does from time to time, when I try to do stuff on my servers. If I could get a lower powered board with IPMI I would use that in a heartbeat as my firewall and sell off the Atom board.
Mostly just powered off, since I don’t need the oompf to run my failover servers. So this is mostly used as an insurance, in case my main VM host dies and I cannot resurrect it. Then I can spin up the important VMs on this server while I work to fix the main VM Server.
This server is obviously grosly overpowered, since all it does is
- Serve ISO files for my VM’s
- Serve as replication target for my virtualized NFS Server, so all VM files gets replicated to this server as a fast storage backup
- Serve as SMB fileshare for my multimedia files, i.e. pictures, videos etc.
The server have two zfs pools which both are mirrors
1 6TB pool
1 12 TB pool
The optane is being used as ZIL for both pools, even though its not really needed - I just had it lying around from when my main VM’s was served from SSD’s.
I also have exported a dataset for the VM servers, if they need more storage that I want to give on the NVME pool on the virtualized truenas server.
This is the main work horse and is currently very much under utilized.
According to stats my ESXi is using 270GB out of 640GB RAM, so plenty of room to grow - and also in teerms of CPU it says its using 4GHz out of 53GHz.
So plenty of room to grow, even considering that of the 270GB RAM, 128 of them is allocated to the truenas server serving NFS back to ESXi.
All the VM’s run off the NFS datastore that is served by the virtualized truenas server - except for the truenas server itself obviously.
Backup strategy
The backup strategy I am using is kind of simple, but when you look at it from the outside it could probably have been done easier. My VM files are stored on the virtualized truenas inside my main VM Server.
- Every hour my virtualized truenas takes a snapshot, but before that happens it ask the VM hosts to flush all data to disk via the ESXi API that truenas is using
- Every time a snapshot is created it gets replicated to my backup truenas server.
- Once per day my virtualized VEEAM servers makes a backup using the ESXI api so the virtual machine is backed up. This happens as weekly full backup and a daily incremental backup during the week.
- Every day these VEEAM backup files are rsynced to my online storage host rsync.net. They have a simple but good offering, where you get SSH access to a ZFS installation where you can either replicate via ZFS or simply rsync data to them. I use rsync, since replicating my raw ZFS datasets instead of the compressed backup files from VEEAM would make my price for this offsite back explode to perhaps 5 times the price I pay now.
So if disaster happens - either self inflicted - because I mess up a virutal machine or an update to a VM has left it in a bad state - I have several options to restore the VM. I can either restore it directly into ESXi via VEEAM - then I would lose any changes for the entire day - or if really important - I could shut down the VM - copy the VM file from my storage backup server from the snapshot that has not been contaminated with my changes into the VM host NFS server - start the VM and I have it running again - only lost at most 1 hour of data.
If my servers die - I can install a new server, install VEEAM somewhere - and then restore the VM’s directly into ESXi from the VEEAM backup files.
So I should be covered in most scenarios that I can think of. Of course if rsync.net loses my data and at the same time I also loses both my virtualized truenas server & my backup truenas server then I am truly lost and would need to start over.
I have considered buying a LTO tape drive and copy the backups to tape and then store the tape offsite - but I have decided that the current setup is good enough for my purpose and if I lose all my servers I will take it as a challenge and build something even better next time :-)
Virtualized servers
Truenas
pool: fast
state: ONLINE
scan: scrub repaired 0B in 00:09:05 with 0 errors on Sun Jan 9 00:09:09 2022
config:
NAME STATE READ WRITE CKSUM
fast ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
gptid/5922f568-7563-11eb-903d-1402ec6581d8 ONLINE 0 0 0
gptid/592d9196-7563-11eb-903d-1402ec6581d8 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
gptid/590d3a28-7563-11eb-903d-1402ec6581d8 ONLINE 0 0 0
gptid/5926c68b-7563-11eb-903d-1402ec6581d8 ONLINE 0 0 0
Which is basically a striped mirror (raid 10). This gives me the best performance and is the recommended way as far as I know when you serve VM’s from ZFS. It also allows me to lose two diske. One in each mirror. Obviously if I lose two disks in one of the mirrors I will have lost all my data, but that is why my data is being replicated to another server.
My 4X1TB SSD’s are being used in a pool, exclusively used as a target for the VEEAM server, so they get a fast write target - and on its own pool - so I don’t destroy the main pool with all the data I write to each each day. The layout of my SSD pool is:
pool: fast_backup
state: ONLINE
scan: scrub repaired 0B in 00:04:57 with 0 errors on Sun Dec 26 00:04:58 2021
config:
NAME STATE READ WRITE CKSUM
fast_backup ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
gptid/d5ab9e2e-89a7-11eb-952f-1402ec6581d8 ONLINE 0 0 0
gptid/d5c17a28-89a7-11eb-952f-1402ec6581d8 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
gptid/d5b0a657-89a7-11eb-952f-1402ec6581d8 ONLINE 0 0 0
gptid/d5c012eb-89a7-11eb-952f-1402ec6581d8 ONLINE 0 0 0
My pools are massively overpowered for my silly needs, but when I started using ZFS I stared myself blind at the silly low transfer rates I could get when I wrote data from the ESXi server. The reason for the low transfer rates from ESXi when you use NFS, is that ESXI forces sync on every single write - which basically tells ZFS that it cannot buffer anything in memory and has to write directly to the pool. This causes massive slowdown when using ZFS, since it cannot do what it normally do - accept the writes in memory and flush whenever. When I was testing I was running with 8 datacenter SSD’s in a quadruple striped mirror and still I was only getting 3-400 MB/s transfer speed - but when I tested locally on the ZFS server I could get several gigabytes per second. So I decided to switch to a NVME pool, which both have higher speed and lower latency. If I had known more I would probably stayed with the 8 SSD’s since they were plenty of sufficient, but I just could not stand to see that my pool that had a theoretical write speed of 2.4GB/s could only do 4-500 MB/s. My NVME pool have a theoretical write speed of 5.8GB/s but in reality on NFS from ESXi its probably only around 1GB/s which is also plenty for my needs, because in reality how often is it you have to write data in such speed for an extended period of time.
Latency is what matters since that gives responsive VM’s. Not transfer speed. Hindsight is 20/20 as they say :-)
DHCP
Obviously I need DHCP, since it would be next to impossible to hook up new machines, mobile devices etc. I have two virtual machines running dnsmasq each serving their own ip range, so whoever answers first gives out an ip address when a client request an ip address. Furthermore the two DHCP servers allow me to have downtime when I am doing software updates etc, since I will always leave one of the DHCP servers running.
On top of the ip ranges the DHCP servers serve - they also work as TFTP/PXE servers, so when I want to install a new virtual machine - I just create the virtual machine and boot it and then I get to choose whether or not I want to install debian or Rocky OS - and then the installation kicks off and installs my preferred packages, ssh keys etc, so when the virtual machine is done installing and has rebooted - I have a server with the basic stuff installed that I can ssh into with my ssh key.
DNS
I also have two DNS servers virtualized. These are running powerdns and are replicating zone changes between them.
When I administer my DNS zones I use PowerDNS-Admin which is running as a docker container on my Docker virtual machine.
This makes my DNS administration for my local network easy and every time i decide to add a a permanent server - it gets a hostname added to the domain that my local network is using.
Docker
My docker host is a virtual machine that runs a range of containers. The containers are administered via portainer that is also running as a docker container itself. On top of the container administration docker container I am also running
- Postfix - my mail server that handles all mail that gets send from my server, i.e. every time a backup has completed, my data has replicated to rsync.net and so forth.
- Transmission - my torrent server, that is being used if I need to download anything that has a torrent file. On my local machine I only have Transmission Remote Gui installed and any magnet links or torrent files are being sent to the server that drops the file(s) to my backup storage server when the download has completed.
- TrueCommand - iX Systems “fleet” panel you can use to administer multiple truenas servers in one window pane. I mostly have this installed to see what its all about. I am not actively using it for anything.
- Kafdrop - A kafka cluster Web ui that allows you to peek into a clusteer and see the brokers, topics and messages even. I am not actively using this, since I am building my own.
Veeam
I have multiple VEEAM servers installed - the reason I have multiple servers is because the community edition of VEEAM can only backup 10 virtual machines. So to get around that limitation I simply have the software installed on multiple servers and then each server handles backup for 10 virtual machines. Obviously this is kind of silly and every time I get more machines that I would like to backup and I have run out of capacity - I have to clone my VEEAM server, apply a new windows serial. It would be nicer if the community edition of the software did not have this limitation, but instead had other limitations - perhaps on size - or a simple rule: You cannot use this for commercial use.
Syslog
I have a VM runnning as a syslog server - this is simply just dumping the syslog entries to files that is a network share that was mounted from my backup truenas server. I don’t use this much, except to get rid of the local logging on those servers that instead pushes their syslog messages to this server - so I have one central place to clean up logs. So this server is only for convenience - if I could be bothered - I would just set up proper cleanup on all of my servers and then I could stop this machine.
DMZ Servers
This blog is being served from a couple of virtual machines running in my DMZ zone
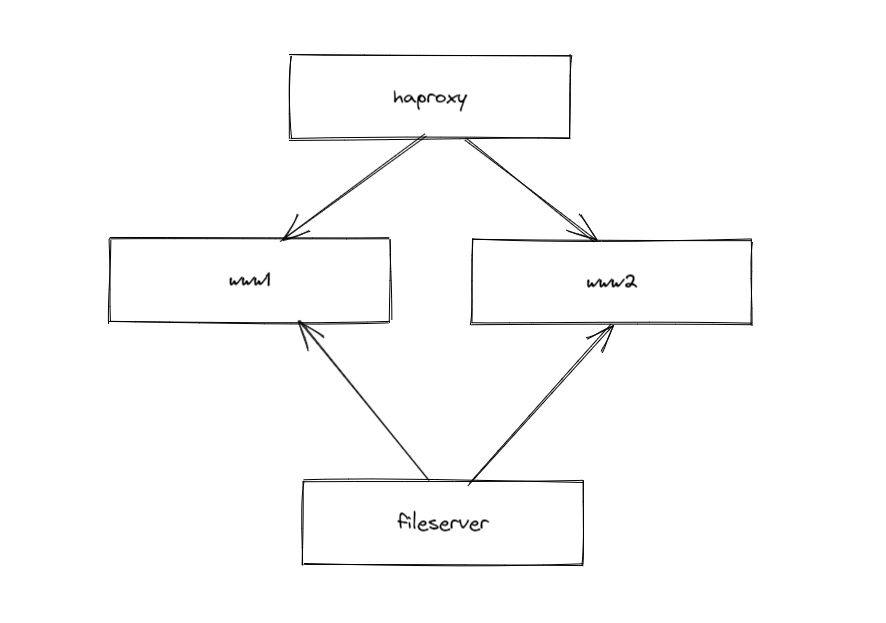
I have two nginx webservers running behind a haproxy server. The webservers get their content from the file server via their NFS mounts. This is a simple setup and to update my blog I just have to update the file server and everything is online.
In the DMZ there are also two DNS servers running the same setup as my internal servers and they also receive zone updates from the internal servers. My DMZ servers are not capable of accessing the internet - except for a few select ip addresses. This is to limit any disaster in case they somehow get hijacked - even thouh I think its unlikely, since they are runnning behind a haproxy and they only serve static data and have no obvious holes. But of course if there is a vulnerability somewhere in the stack anything can be hacked.
Network topology
My internet ends in my firewall that has two networks internally.
The LAN zone and the DMZ zone.
All my servers run in the LAN, except for those that need to be accessed from the outside they run in the DMZ.
MY VM hosts have two network cards, each in their own zone - so my VM hosts can host both servers that run in the DMZ and on the LAN. Routing between these two zones are for obvious reasons not possible, except through the firewall that only allow traffic to flow into the DMZ but not traffic that originate from the DMZ to go anywhere. On top of the physical separation I am also running with VLAN id in the DMZ - but the servers are unaware of the VLAN id - it gets tagged on the firewall and only traffic with the correct VLAN id gets picked up by my VM hosts on their DMZ network interface. I am hoping that this extra layer will protect me in case I accidently switch some cables, so I dont accidently put my web servers onto the LAN.